Before Spark, there was Hadoop
Hadoop is an open source framework utilized for efficiently storing and processing large datasets. It enables the clustering of multiple computers to analyze massive datasets in parallel. Hadoop consists of four main modules:
Hadoop Distributed File System (HDFS): A distributed file system that runs on standard or low-end hardware. It offers improved data throughput, high fault tolerance, and native support for large datasets.
Yet Another Resource Negotiator (YARN): Responsible for managing and monitoring cluster nodes and resource usage. It schedules jobs and tasks for efficient resource allocation.
MapReduce: A framework that facilitates parallel computation on data. The map task converts input data into key-value pairs that can be computed, and the output is consumed by reduce tasks to aggregate the results into the desired output.
Hadoop stands as the cradle of distributed data processing domain. Strictly speaking, Hadoop is not merely a framework, but a comprehensive ecosystem. For instance, MapReduce is responsible for distributed computing, while HDFS manages the storage of vast amounts of files.
The problems with MapReduce
The advent of the MapReduce model signifies a significant leap in the realm of distributed data processing.
However the demands for big data processing have become increasingly complex, and the problems with MapReduce have become more apparent. Typically, we keep the input and output data of MapReduce on HDFS. Many times, complex tasks such as ETL and data cleansing cannot be completed by a single MapReduce operation, so multiple MapReduce processes need to be connected.
In this approach, each intermediate result has to be written to HDFS for storage, which incurs a significant cost (don’t forget that each piece of data on HDFS needs multiple redundant copies). Moreover, since it essentially involves multiple MapReduce tasks, scheduling becomes more complicated, making real-time processing infeasible.
Spark to the rescue
Regarding the aforementioned issue, wouldn’t it be much faster if we could save the intermediate results in memory? The main obstacle to doing so is the requirement for distributed systems to tolerate a certain degree of faults, also known as fault-tolerance. Keeping the data only in memory poses a problem because if a computing node fails, the other nodes cannot recover the lost data and can only restart the entire computing task, which is unacceptable for clusters with hundreds or thousands of nodes.
In general, there are only two approaches to achieve fault-tolerance:
- store the data externally (e.g., HDFS)
- create multiple copies.
However, Spark introduces a third approach - recompute. The ability to do so is dependent on an additional assumption: that all computational processes are deterministic. Spark draws inspiration from functional programming and presents RDDs (Resilient Distributed Datasets), which are essentially “resilient distributed datasets.”
RDDs are read-only collections of partitioned data. They can either originate from immutable external files (e.g., files on HDFS) or be derived from other RDDs through deterministic operations. RDDs are connected through operators to form a directed acyclic graph (DAG), as shown in the simplified example in the diagram, where nodes represent RDDs and edges represent operators.
Returning to the previous question, how does RDD achieve fault-tolerance? It is quite simple - every partition in an RDD can be computed deterministically. Therefore, if a partition is lost, another computing node can recalculates it using the same process starting from its predecessor node, resulting in an identical RDD partition. This process can be recursively repeated.
RDD’s data is composed of multiple partitions distributed across machines in the cluster. Furthermore, RDDs also include dependency information for each partition and a function indicating how to compute the data for that partition. Depending on the execution method, the relationships between RDDs can naturally be classified into two types: narrow dependencies and wide dependencies. For example:
Operators such as map() and filter() form narrow dependencies, where each produced partition only depends on one partition in the parent RDD.
Operators such as groupByKey() form wide dependencies, where each produced partition depends on multiple partitions in the parent RDD (often all partitions).
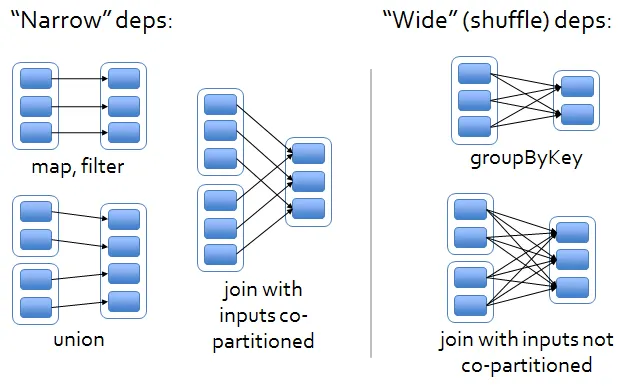
During execution, narrow dependencies can be easily computed in a pipelined manner - each partition is sequentially passed through the operators from beginning to end. However, wide dependencies require waiting for all partitions in the preceding RDD to finish computing. In other words, wide dependencies act as a barrier that blocks until all previous computations are completed. The entire computation process is segmented into multiple stages, as shown in the right diagram.
Those familiar with MapReduce may have already noticed that wide dependencies essentially resemble a MapReduce process. However, the difference is that the intermediate results are not written to HDFS, but are kept in memory. This approach is much faster than MapReduce, and it also avoids the overhead of writing to HDFS.